3 NHANES
4 Increasing access to the NHANES 1988-2018 surveys & mortality linkage data via a user-friendly Stata program
Xinran, MHS, Johns Hopkins University, School of Medicine
Background: We are developing skills that allow us to access publicly available large databases that may be queried to answer fundamental questions about the publics health. These datasets might exist in formats unfamiliar to Stata users or in sizes that cripple ones workflow.
In our first two weeks, we curated a dataset with all the mortality records in the United States from 1959-2017 and wrote a basic Stata script that output a two-way plot showing annual trends in number of deaths during this period. In the subsequent two weeks we wrote a Stata program, mortality, that allows the user to define the time-period of interest, plus other parameters such as cause-of-death, and ultimately produce a similar two-way plot with the convenience of a Stata command.
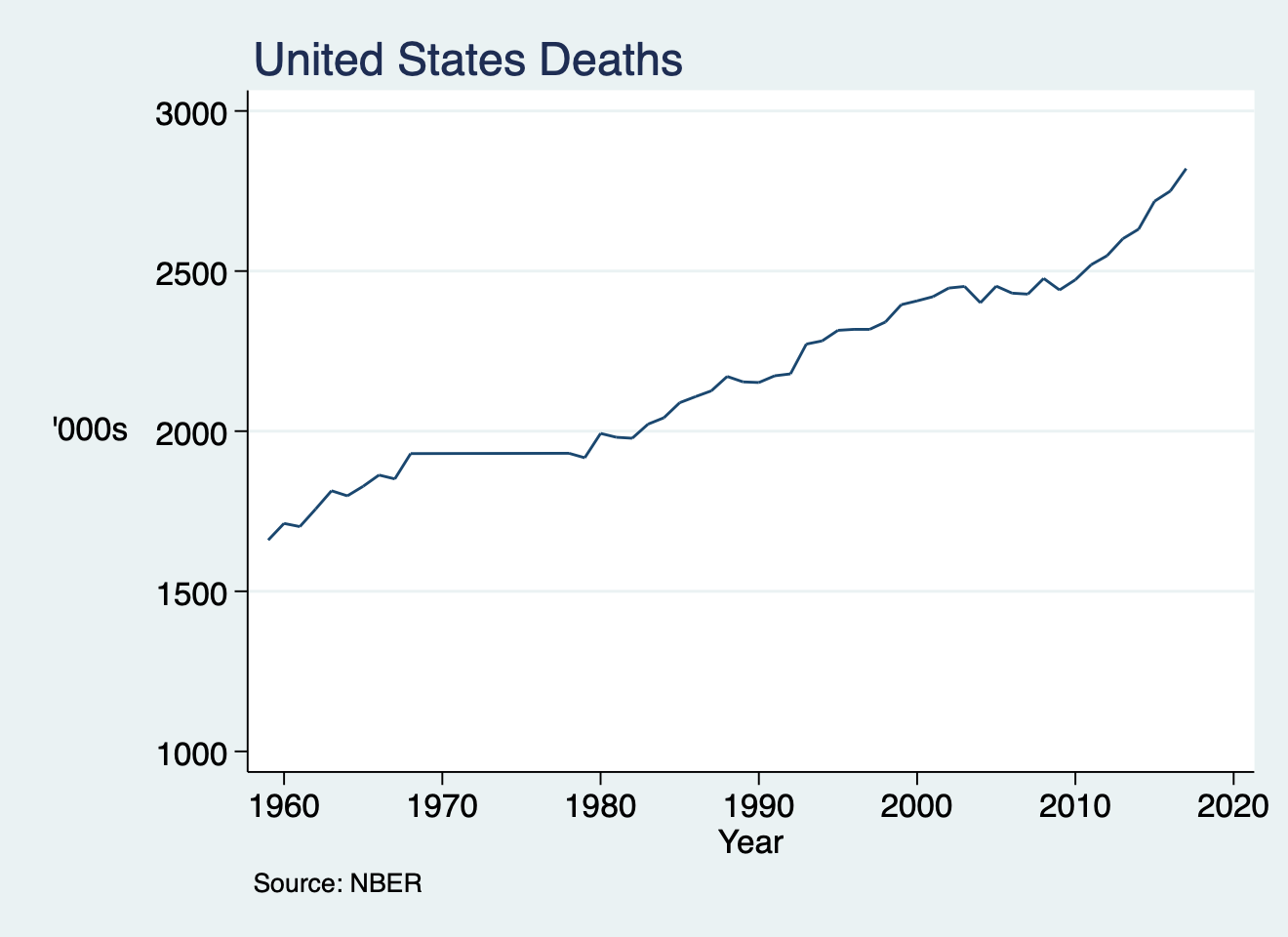{kind=link}
Our goal for the second-half of the class is to leverage this experience to give Stata users access to the entire range of NHANES surveys via a simple command, nhanes, with several user-defined options. We have not yet articulated what these options are but will do so on an emerging basis each week.
Today let’s start by reading in the alpha-version of this program, which we adopted from Chapter: r(mean) of the PH.340.600 book. Depending on your Stata edition, this program will either import a dataset with 20,000 observations and 3600 variables or 20,000 observations and 22 variables:
Methods: For Stata/BE or IC users this current program outputs an NHANES dataset with 22 pre-specified variables. Over the next week we shall release the next iteration of the program, which will allow the user to list the variables they wish to be imported from the CDC website.
Results: When a Kaplan-Meier graph pops up on your screen, that will be your cue that the program has run to completion and that you have an NHANES III dataset in your pwd.
. qui do https://raw.githubusercontent.com/jhustata/book/main/nhanes-alpha.ado
. set scheme s2color
. nhanes
. use nh3andmort, clear
(NHANES 1988-1994, survey & mortality)
. di "obs: `c(N)' & vars: `c(k)'"
obs: 19599 & vars: 3643Conclusions: NHANES is a large databased with 19599 participants surveyed and 3643 questionnaire, exam, and lab items captured. It is soon going to be fully accessible to Stata users, in no small part because of this humble capstone project.
As we establish our workflow, updates to our program will be published on a weekly basis and the URL will be sent to the student team as well as the teaching team in the first five minutes of each class session. A question not to ask: shall we ever need to annotate our .do files if we can offer much richer documentation in e-book built using .html?
Acknowledgments: We initially published our Stata output in a Jupiter-book hosted by Github. All the .html content of the book was produced in a Python environment; however, Stata .html output will gradually replace the Python-based output of the book as we truly become advanced Stata users!
VS Code terminal is our IDE choice for committing and pushing our git content to our hub and have established a seamless process for updating our publication.
References:
- https://jhustata.github.io/book/jjj.html
- https://jupyterbook.org/en/stable/start/your-first-book.html
- https://www.stata.com/stata-news/news36-1/spotlight-markdown/
- https://wwwn.cdc.gov/nchs/data/nhanes3/1a/adult.sas
- https://jhustata.github.io/class700/intro.html
- https://www.jhsph.edu/courses/course/37447/2022/340.700.71/advanced-stata-programming
- Muzaale AD. Databases for surgical health services research: National Health and Nutrition Examination Survey. Surgery. 2019 May;165(5):873-875
- https://www.ssc.wisc.edu/~hemken/Stataworkshops/dyndoc%20review/Review.html